[2410.11758] Latent Action Pretraining from Videos
GitHub - LatentActionPretraining/LAPA: [ICLR 2025] LAPA: Latent Action Pretraining from Videos
Introduction
LAPA (Latent Action Pretraining From Videos) 是一种利用不含动作标签的视频数据来训练 VLA 模型的方法。目前 VLA 范式需要大量的机器人数据,而遥操作等方法收集数据的成本极为高昂,因此如果能利用互联网上的视频作为数据集,提取其中的动作语义,便能缓解数据稀缺这一挑战。
Pipeline
LAPA 的训练主要分为三个阶段
- Latent Action Quantization
- Latent Pretraining
- Action Finetuning
直观地理解,这三个阶段分别做了三件事
- 训练一个模型(Encoder),让它通过看视频的变化,学会一套描述这些变化的“动作词汇”,并把它们表示为离散的数字代码
- 训练一个大脑(VLM),让它学习如何根据指令和看到的画面,从第一步学到的“动作词汇”表中选择正确的“动作词汇”来完成任务
- 告诉这个大脑,如何把学习到的“动作词汇”转为机器人实际可以执行的动作
下面我们具体来看看这三个阶段都是如何设计的。
Latent Action Quantization
这个阶段主要借鉴了 VQ-VAE 的思想,模型分为 encoder 和 decoder 两个部分。
encoder 接受当前帧 和一个未来帧 ,输出一个隐变量 ,decoder 通过 和 重建出
具体来看,模型的结构依照 C-ViViT 实现,与之不同的是,decoder 部分只用到了 Spatial Transformer,这是因为我们只用到了 和 这一对图片
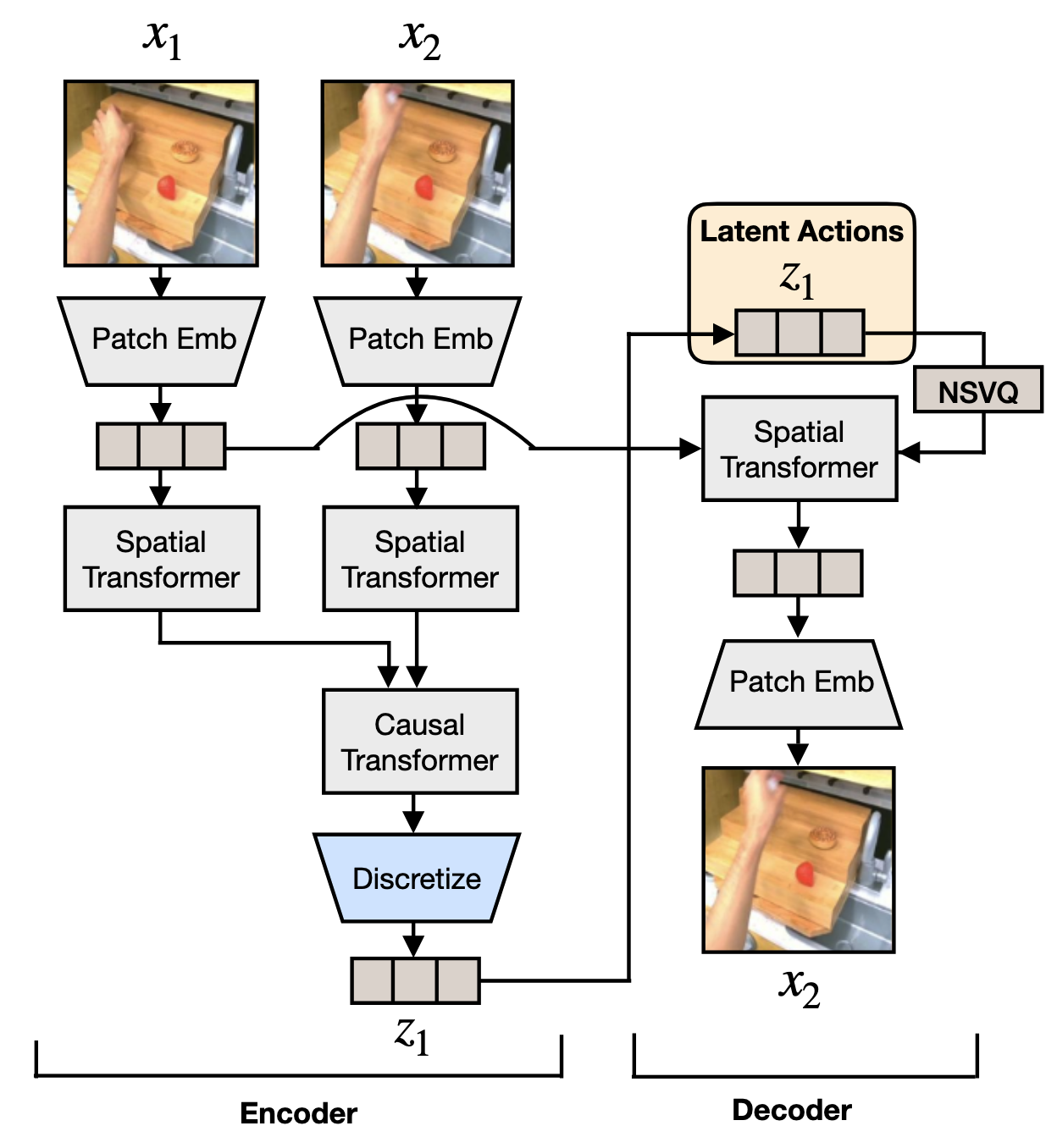
Latent Action Quantization Model |
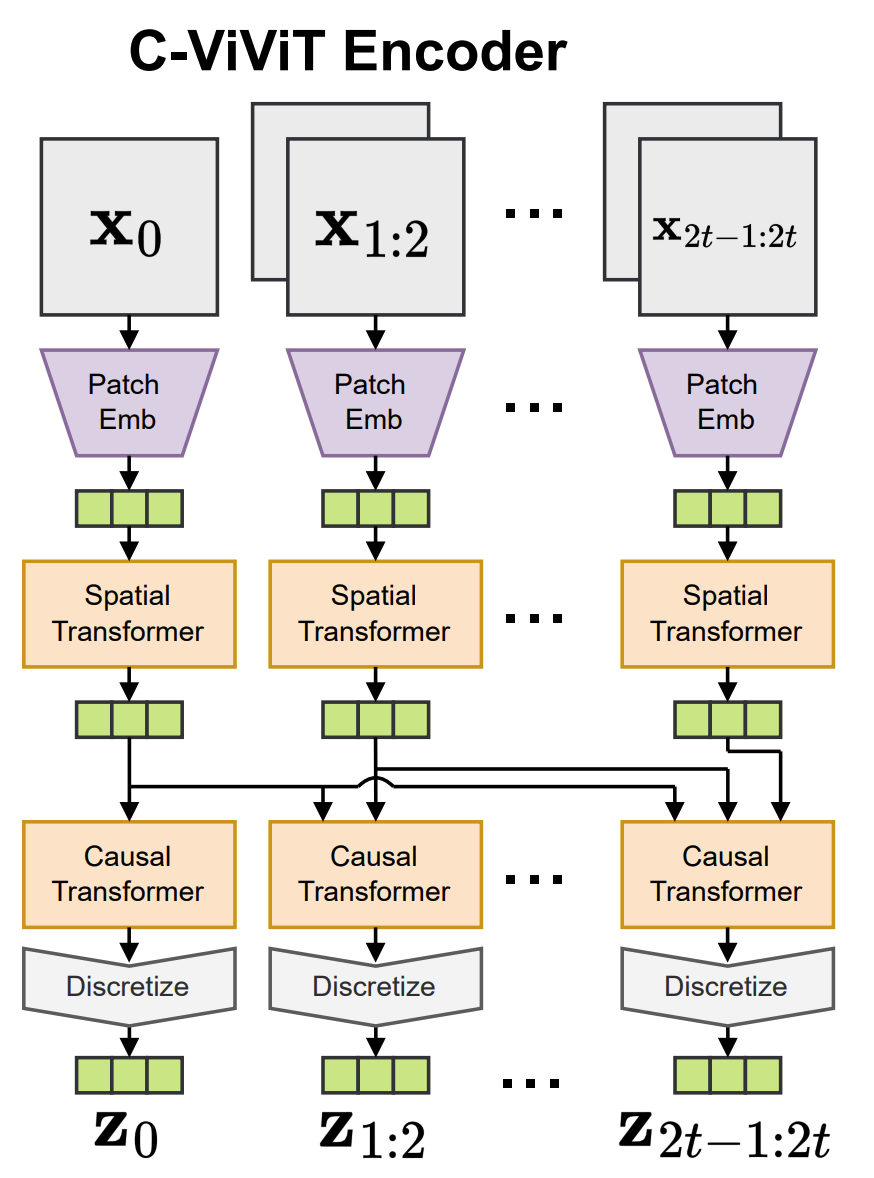
C-ViViT Encoder, Decoder 是 Encoder 的倒置 |
这里的离散化 (Discretize) 过程值得注意:
在之前的过程中输入 和 经过 Spatial Transformer 和 Causal Transformer 之后,输出了两个特征图,接着通过一个 CNN 来得到两个 token 序列 和 ,这个序列长度由 CNN 的 kernel size, stride 等决定
定义 这代表了两帧之间的变化,也就蕴含了动作信息。
要把 量化,根据 VQ-VAE,在 codebook z 中找到与 最近的 embedding:
接着 和 的 embedding 输入到 Spatial Transformer 中解码出
这里用到了一个 trick NSVQ,其解决了量化操作的不可导性导致的梯度无法传播,这里不赘述。
Latent Pretraining
Latent Pretraining 的流程如下:
- 对于 用上一步的 encoder 输出的 来标记
- 然后在给定当前帧 和语言指令的条件下让 VLM 预测
其中 VLM 使用 Video-LLaMa 并且使用一个独立的 latent action head (codebook 大小的 MLP) 来预测 在训练过程中,只冻结 vision encoder 而不冻结 language model
Action Finetuning
Action Finetuning 的流程如下:
- 丢弃 VLM 中的 latent action head,并用一个新的 action head 代替。这个 action head 输出机器人可以执行的动作,例如 delta eef 等
- 只冻结 vision encoder 而不冻结 language model,用一个小的 action-labeled 数据集微调
与 OpenVLA 一样,这里需要把 action 离散化。
Experiments
这里我主要关注的是 LAPA 从人类操作视频学习的效果。
实验的使用的预训练数据集是 Something-Something V2,视频理解领域的经典数据集,包含 220K 人类操作的视频。
预训练之后分别在仿真 SIMPLER 和现实世界进行测试 这里的 Scratch 代表直接微调一个 VLM (即第三个过程),VPT 和 UniPi 是两个 baseline。
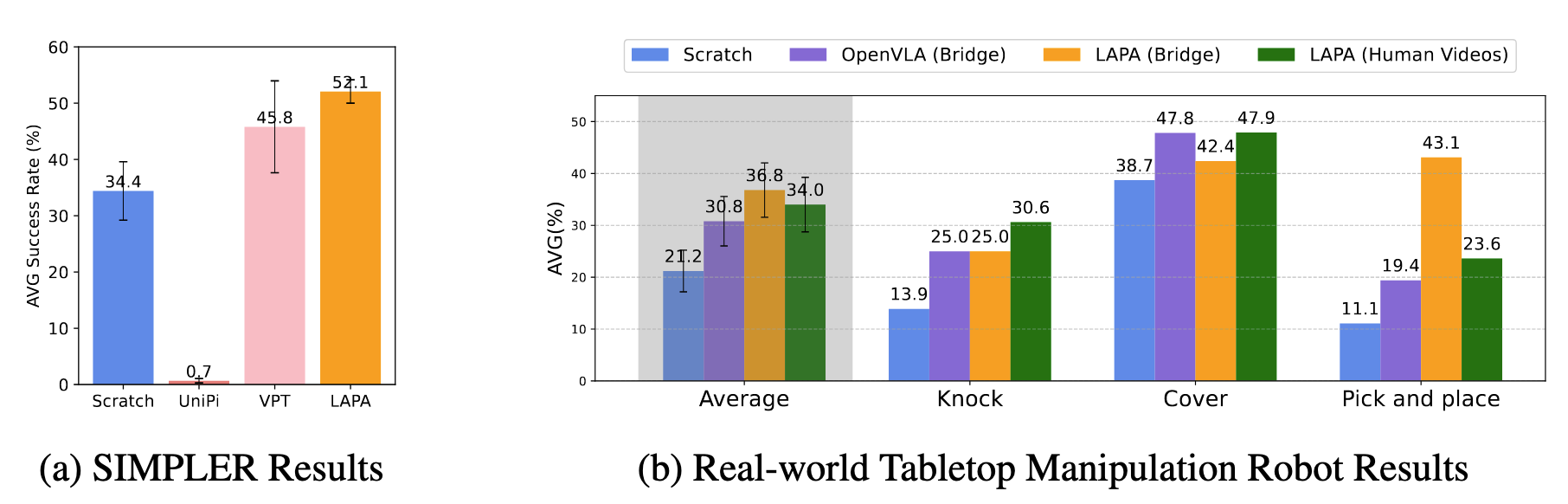
这里最值得注意的结果是 LAPA(Bridge) 和 LAPA(Human Videos) 的对比,可以看到两者的平均成功率相差不大,这说明了 LAPA 可以一定程度上克服人类和机器人在形态学上的差异导致的学习困难。从原始的人类操作视频中直接学习是一个 promising 的方向。
Comments
以往许多从视频中学习的工作(如 AVDC General Flow) 都是学习一个模型,使其能够根据当下的观察和语言指令预测出将来的轨迹,再通过 IK 把这个轨迹反解出来执行,这种方式显式建模了模型学到的 action 表示。而 LAPA 则依赖于 latent action。
个人认为,latent 表示还是太黑盒了,很难去直观理解学习的效果,只能靠和 Scratch 的成功率对比来侧面反映。显式地表示,例如预测出一个轨迹,就能从这个轨迹是否合理,是否平滑来判断学习效果,更加直观可控。
LAPA 的最大创新点还是 VQ-VAE 架构,为什么要这样做呢?论文给出的解释是为了便于 VLM 预测,需要将动作表示离散化。但是这么做也带来一个问题:codebook 的大小是固定的,也就是说模型能够学到的“动作词汇”是有限的。
例如把一个杯子拿起来,和把一个苹果拿起来的动作,模型在学习过程中其实更多学到的是“拿起杯子”和“拿起苹果”这两个动作,而不是“拿起”这个通用动作,也就是说模型学习的仍然是 specific 的技能,但是如上文所说,这种技能是有限的,也就无法覆盖所有的动作,泛化性肯定是不足的。当然,这都是我的个人理解,具体学习到的是什么层级的动作表示还是取决于”latent action”究竟是什么样的,然而这是一个黑盒,我们无法直接判断。